08 Nov 2018
Abstract
Studies of the peopling of the Americas have focused on the timing and number of initial migrations. Less attention has been paid to the subsequent spread of people within the Americas. We sequenced 15 ancient human genomes spanning Alaska to Patagonia; six are ≥10,000 years old (up to ~18× coverage). All are most closely related to Native Americans, including an Ancient Beringian individual, and two morphologically distinct “Paleoamericans.” We find evidence of rapid dispersal and early diversification, including previously unknown groups, as people moved south. This resulted in multiple independent, geographically uneven migrations, including one that provides clues of a Late Pleistocene Australasian genetic signal, and a later Mesoamerican-related expansion. These led to complex and dynamic population histories from North to South America.
[Image]
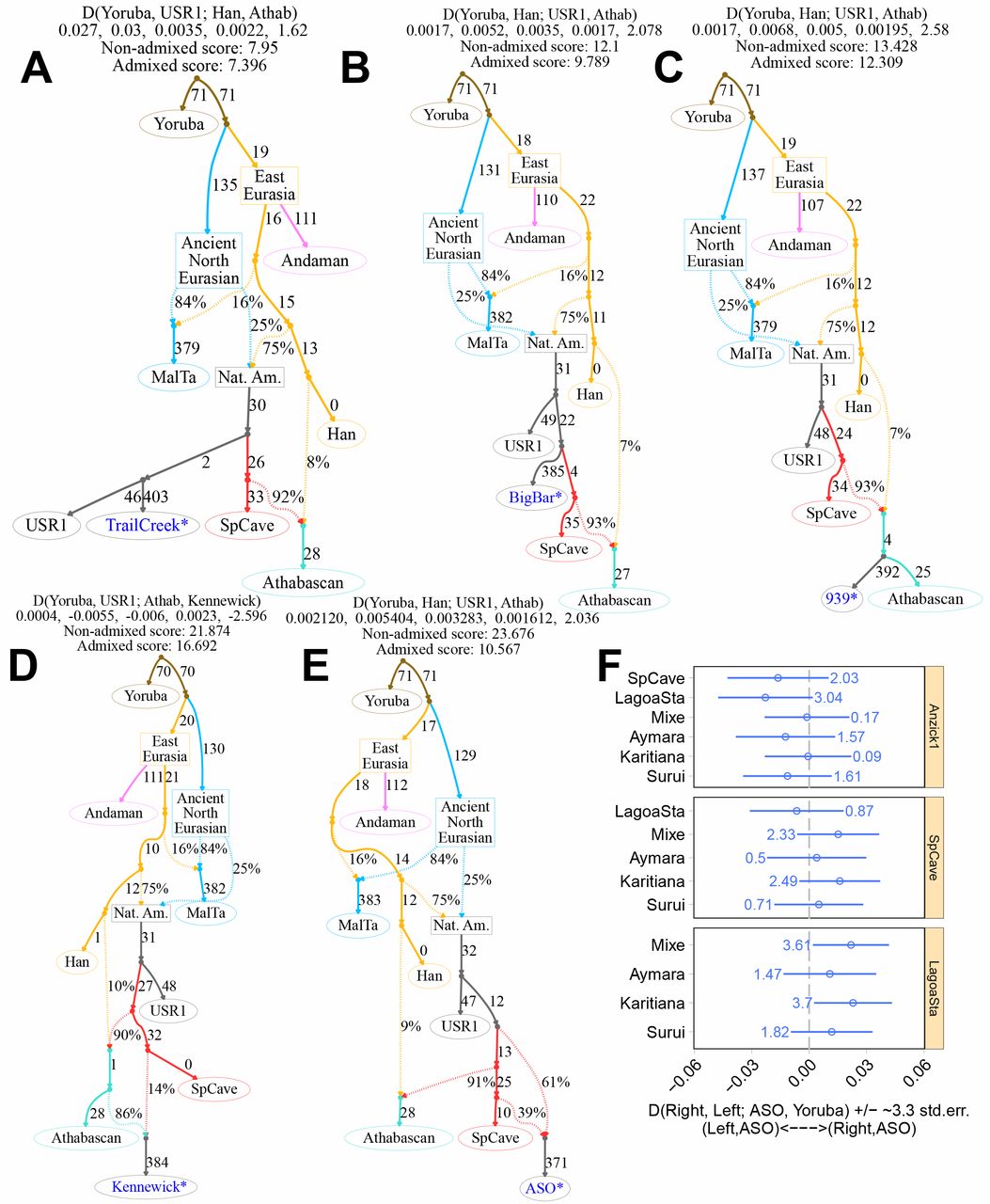
Fig. 2 Admixture graphs modelling the ancestry of ancient North American genomes.
We enumerated all possible extensions of the seed graph (13) where we added Trail Creek (A), Big Bar (B), 939 (C), Kennewick (D), and ASO (E) as a “non-admixed” or an admixed population, and optimized the parameters for each topology using qpGraph. In each graph, the test population is shown in blue. We show the best-fitting model for each genome as inferred from the final fit score. Above each graph, we show: the four populations leading to the worst D-statistic residual; the observed value for such statistic, and the expected values under the fitted model, the residual, the standard error of the residuals and a Z-score for such a residual; and the model fit score. Numbers to the right of solid edges are proportional to optimized drift; percentages to the right of dashed edges represent admixture proportions. In each graph we highlight the test genome in blue.
(F) Error-corrected D-statistics restricted to transversion polymorphisms testing the genetic affinity between ASO and different SNA pairs. Points represent D-statistics and error bars represent ~3.3 standard errors (P ~ 0.001). For each test, we show the absolute Z-score beside its corresponding D value. A pool of the five sequenced individuals represents the Lagoa Santa population.